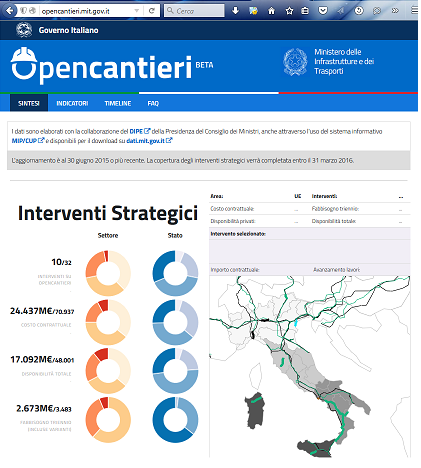
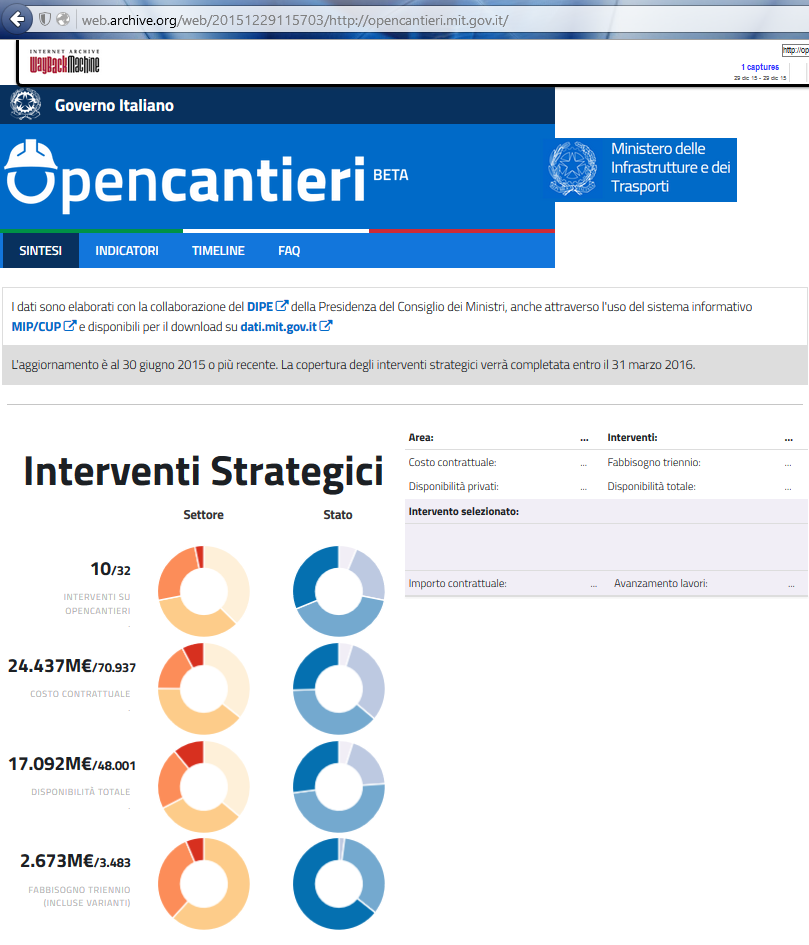
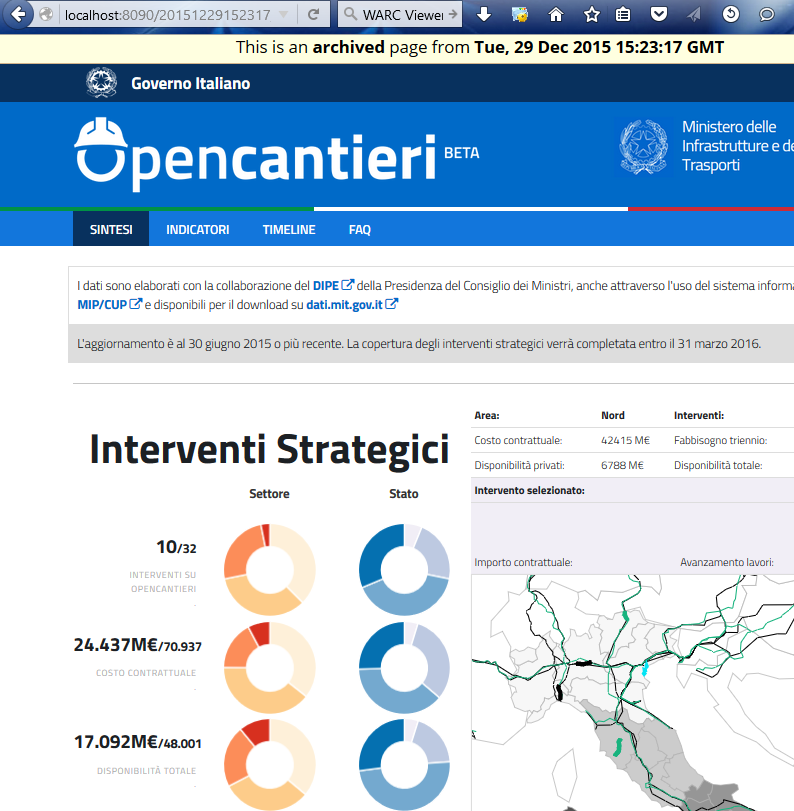
Difficile a dirsi, sicuramente il bilancio di ciò che è accaduto nel 2016 è piuttosto “articolato”. Fatti salienti del 2016:
a) entra in vigore il Regolamento europeo eIDAS; [1]
b) viene modificato il CAD in materia di riorganizzazione delle PA; [2]
c) si pronuncia il Garante della Concorrenza sul PARER; [3]
d) il numero dei conservatori accreditati supera quota 70; [4]
e) gare pubbliche inerenti la conservazione aggiudicate con un ribasso anche dell’80%;
f) slitta l’obbligo di una PA totalmente senza carta previsto per Agosto; [5]
g) si dibatte sul ruolo dei “Conservatori Pubblici” nel sistema paese; [6]
h) viene emanato il nuovo codice degli appalti pubblici [7]
Un primo risultato è la percezione di un servizio “da vendersi al chilo”, l’appiattimento dell’offerta sul servizio di conservazione, la trasformazione del medesimo in una commodity ove l’unica cosa che conta è il prezzo. Purtroppo tutto ciò a discapito della qualità, e certo non aiutano quei professionisti sul mercato, che non sanno cosa sia un titolario di classificazione, a ribaltare questo concetto; anzi, taluni sostengono che la figura di un archivista non sia neppure necessaria in un’azienda che fa conservazione ! ( in sostanza come dire che per fare un muro non serva un muratore … ) - ( punti d,e ).
Questa percezione, ha portato gli enti a una sorta di “auto-protezionismo” e alla proliferazione di quei “Conservatori Pubblici” come unici interlocutori, in grado di gestire con cognizione di causa, le relative esigenze. A ciò si aggiunge il capzioso sistema di approvvigionamento della PA, che tra convenzioni, mercati elettronici che non offrono la possibilità di distinguersi e concorrenti che non necessitano di transitare da essi, non stimola certo i continui investimenti che il voler essere competenti obbliga a dover fare - ( punti c,g,h ).
Il legislatore nel 2016 talvolta ha spinto e talvolta ha frenato, facendoci ricadere nel tranello del “tanto prorogheranno”, “tanto non lo farà nessuno”, “tanto non abbiamo gli strumenti per farlo”, attitudine che pian piano stavamo sradicando, almeno nel mondo della legislazione digitale, ma che nell’anno in chiusura, in vari fronti è riemersa - ( punti a,b,f ).
A questo punto, il 2017 ci porrà inevitabilmente a un bivio e porterà a suddividere i conservatori privati in due categorie.
La prima categoria, è quella a cui appartengono coloro che si sono accreditati “giusto perché il marketing ritiene sia importante”, “giusto perché si è accreditato anche il nostro competitor”, ”giusto perché tanto, a parte le fatture elettroniche, non conserva niente nessuno”, “giusto per fare cross-selling sul parco”, che classificandosi alla stregua di venditori di spazio su disco, sulle medesime leve di tipologia di servizio e pricing faranno la loro battaglia.
La prima categoria, è quella a cui appartengono coloro che si sono accreditati “giusto perché il marketing ritiene sia importante”, “giusto perché si è accreditato anche il nostro competitor”, ”giusto perché tanto, a parte le fatture elettroniche, non conserva niente nessuno”, “giusto per fare cross-selling sul parco”, che classificandosi alla stregua di venditori di spazio su disco, sulle medesime leve di tipologia di servizio e pricing faranno la loro battaglia.
La seconda vedrà i conservatori evolversi in “veri gestori del documento digitale”, in coloro che pensano “il documento digitale dal momento della produzione alla sua conservazione e fruizione”, che sanno che “il consolidamento probatorio di un documento è solo la conseguenza della sua corretta gestione e non il suo scopo” e che sono “guida e driver nel portare cultura digitale nel sistema paese”.
E’ evidente che se si vuole che questa seconda specie sopravviva e prosperi con queste caratteristiche, l’ambiente in cui opera deve esserle favorevole: lasciando che nel processo di acquisto possa essere premiata e valorizzata l’interezza del servizio offerto, facendo in modo che le Istituzioni e le Regioni siano i primi alleati verso la cultura del digitale e non il peggior competitor da affrontare, incoraggiando una scelta consapevole che privilegi la competenza e la qualità, ricordando che i documenti digitali sono prima di tutto un bene da tutelare.
Credere che tutti i conservatori offrano lo stesso servizio, è come pensare che ogni vino sia uguale, io a Capodanno brinderò con un “Valdobbiadene Superiore di Cartizze”, auguro a Voi che possiate, come me, brindare al 2017 con un ottimo vino e gestire i Vostri documenti con un valido conservatore
“Per un sereno 2017 e per tutti gli anni a venire, come da massimario di scarto!”
“Per un sereno 2017 e per tutti gli anni a venire, come da massimario di scarto!”
[1] Regolamento UE n° 910/2014 sull’identità digitale – eIDAS (electronic IDentification Authentication and Signature) - http://www.agid.gov.it/agenda-digitale/infrastrutture-architetture/il-regolamento-ue-ndeg-9102014-eidas
[2] DECRETO LEGISLATIVO 26 agosto 2016, n. 179 - Modifiche ed integrazioni al Codice dell'amministrazione digitale, di cui al decreto legislativo 7 marzo 2005, n. 82, ai sensi dell'articolo 1 della legge 7 agosto2015, n. 124, in materia di riorganizzazione delle amministrazioni pubbliche. (16G00192) (GU Serie Generale n.214 del 13-9-2016) note: Entrata in vigore del provvedimento: 14/09/2016 - http://www.gazzettaufficiale.it/eli/id/2016/09/13/16G00192/sg
[3] Bollettino n. 45/2016 del 19/12/2016 - AS1325 -ACCORDI SOTTOSCRITTI DALL’ISTITUTO PER I BENI ARTISTICI CULTURALI E NATURALI PER I SERVIZI DI CONSERVAZIONE DEI DOCUMENTI INFORMATICI CON ENTI E AMMINISTRAZIONI LOCALI - http://www.agcm.it/bollettino-settimanale/8481-bollettino-45-2016.html
[5] Consiglio dei ministri n.125/5566 – 10 Agosto 2016
[6] Convegno ANAI - I depositi d'archivio e i documenti digitali: il ruolo dei conservatori pubblici http://new.archivisti2016.it/17-marzo/item/119-anai-i-depositi-d-archivio-e-i-documenti-digitali-il-ruolo-dei-conservatori-pubblici
[7] DECRETO LEGISLATIVO 18 aprile 2016, n. 50 - Attuazione delle direttive 2014/23/UE, 2014/24/UE e 2014/25/UE sull'aggiudicazione dei contratti di concessione, sugli appalti pubblici e sulle procedure
d'appalto degli enti erogatori nei settori dell'acqua, dell'energia, dei trasporti e dei servizi postali, nonche' per il riordino della disciplina vigente in materia di contratti pubblici relativi a lavori, servizi e forniture. (16G00062) (GU Serie Generale n.91 del 19-4-2016 - Suppl. Ordinario n. 10) - Entrata in vigore del provvedimento: 19/04/2016 – http://www.gazzettaufficiale.it/atto/serie_generale/caricaDettaglioAtto/originario?atto.dataPubblicazioneGazzetta=2016-04-19&atto.codiceRedazionale=16G00062